
It’s one thing to train a model in a notebook. It’s another to scale that model across multiple clouds, regions, and time zones—scoring millions of events in near-real-time.
Energy-Based Models (EBMs) give you power. But that power has a price: compute, latency, and orchestration at scale.
To operationalize autonomous detection and response, you need to architect your system with the same rigor you apply to production infrastructure. This post breaks down what it takes to go from “we trained a model” to “we detect and respond across the globe in under 100ms.”
🧠 The Mental Model: Detection as a Global Service
Think of anomaly detection like a CDN for risk:
- Data comes in from multiple regions.
- Each region needs low-latency inference for scoring.
- Models must stay synchronized and version-controlled.
- Response logic must execute locally but report globally.
This isn’t a batch job. This is a distributed real-time inference network—with security consequences.
🛠️ Key Components of the Infrastructure
✅ 1. Regional Inference Nodes
Deployed in proximity to data sources (e.g., GCP regions, AWS AZs)
→ Reduce latency, minimize egress
→ Host TorchScript-compiled EBM models
→ Serve inference via REST or streaming
✅ 2. Centralized Model Registry + Sync Layer
Manages:
- Versioned models
- Canary vs. production rollouts
- Drift detection
- Global synchronization using CDN or blob storage (e.g., GCS/S3 + Cloudflare)
✅ 3. CI/CD for Models + Playbooks
Models and playbooks are promoted through:
- Simulated testing environments
- Canary regional deployment
- Performance regression tracking
- Cost characteristics
✅ 4. GPU Tiering
- T4 or A10 GPUs for real-time scoring (~10k–50k events/sec)
- A100/H100 for periodic retraining or large batch inference
GPU usage is elastic and scheduled via K8s (GKE, EKS, or AKS) with autoscaling.
✅ 5. Telemetry + Observability
Every detection, score, and action is:
- Logged in structured format
- Shipped to Prometheus, Loki, and Grafana dashboards
- Correlated with cost and latency metrics
- Ingested into the tamper-evident blockchain
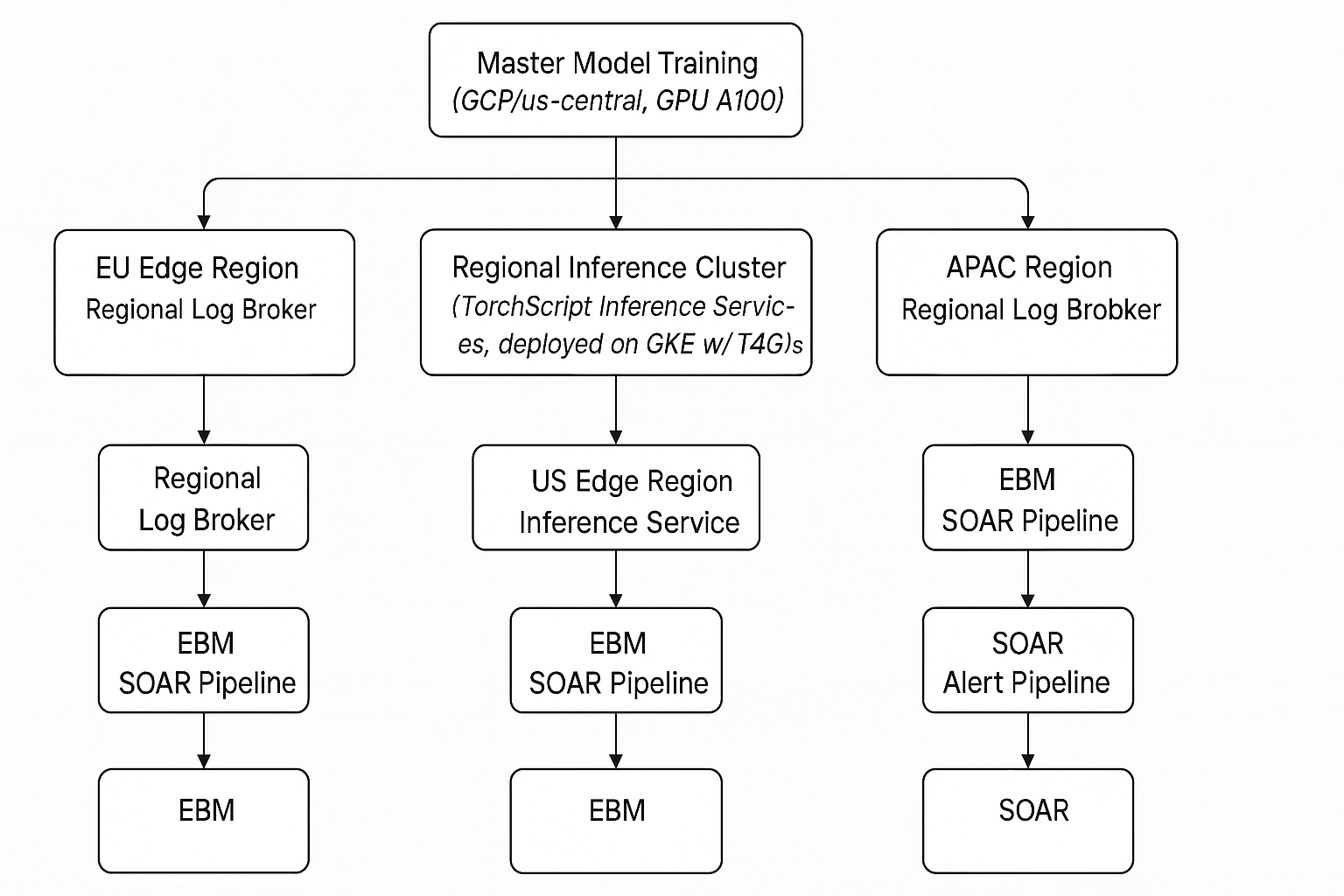
Example high level global architecture
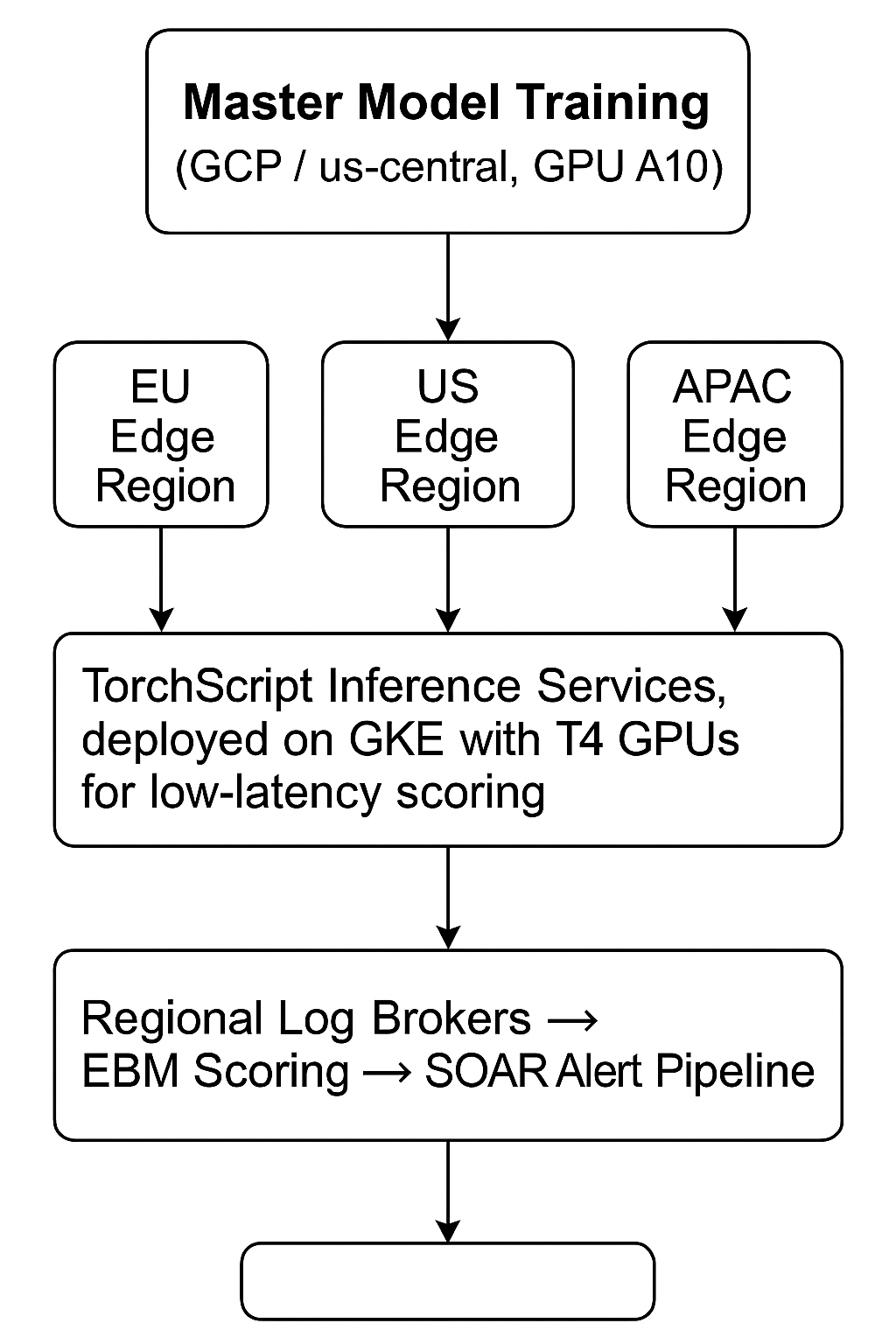
A different sandbox architecture
🔍 Real Example: Three-Region Risk Detection Cluster
A multinational organization deployed EBMs across three continents:
- Each region hosts an inference node behind a lightweight API gateway.
- Models sync every 24 hours—or immediately if hotfix thresholds are breached.
- GPU nodes are burstable and scheduled with cost ceilings.
- The average end-to-end detection latency (from log ingestion to action)
- Under 97ms with 99.9993% accuracy.
- Inference latency (p95) < 100ms per event
- Model sync time < 5 seconds per region update
- Model drift (energy Δ) < 10% shift in energy distribution week-over-week
- Training runtime < 2 hours per regional batch
- GPU utilization 60-90% (training), 30-50% (inference)
💰 Budgeting for Real-Time Defense
| Component | Est. Cost Range (Monthly) |
|---|---|
| T4 GPU (real-time scoring) | $300–$500/node |
| A100 GPU (training) | $2.50–$3.00/hr (spot pricing) |
| Blob/CDN distribution | $50–$200/month depending on model size |
| Observability stack | $150–$500/month |
Compare that to one critical incident that goes undetected—this is cheap insurance.
🧩 Why Infra Is a Strategic Lever
| Constraint | Without Infra Planning | With Infra Strategy |
|---|---|---|
| Latency | Centralized scoring delays action | Local scoring = fast response |
| Model freshness | Undetected drift, stale logic | Versioned updates, drift monitoring |
| Cost efficiency | Idle GPU waste or over-provisioning | Elastic, job-based GPU usage |
| Global consistency | Inconsistent detections across regions | Synced models and logic everywhere |
Security isn’t just what you detect. It’s where and how fast you detect it.
🎯 Your Move
Ask yourself:
- Can your detection pipeline handle burst traffic?
- Are your models versioned, tested, and regionally deployable?
- Is your response logic scalable—or centralized and brittle?
If you don’t know, your infrastructure might be the bottleneck.
👉 Build your detection like a global product. The threats are distributed. Your defenses should be too. Read the full white paper or dive into the latest podcast episode to learn more.